เปรียบเทียบสตริงด้วย Rabin-Karp Algorithm
ไม่ว่าจะเขียนโปรแกรมเพื่อใช้งาน หรือทำเพื่อเขียนแข่ง competitive ก็หนีไม่พ้นการเปรียบเทียบสตริง ในโพสต์นี้เราจะมาดูว่านอกจากวิธีเทียบตรงๆแล้ว Rabin-Karp Algorithm จะช่วยอะไรได้บ้าง

ไม่ว่าจะโจทย์เขียนโปรแกรม หรือเขียนโปรแกรมทั่วๆไป มันจะมีปัญหาลักษณะว่าให้เปรียบเทียบ สตริง 2 ตัว ไม่ว่าจะเป็นเปรียบเทียบสตริง(String) กันตรงเลยว่าเท่ากันไหม หรือถามว่าสตริง x เป็นสตริงย่อย(Sub-String) ของ สตริง y หรือเปล่า
โดยทั่วไปแล้วการหาสตริงย่อยมักจะเจอเยอะกว่า และมีอัลกอริทึมหลายตัวที่พยายามพัฒนาในจุดนี้เหมือนกัน ทำให้เกิดเป็นวิธีการหา pattern ต่างๆ ซึ่งโพสต์นี้เราจะมาดูอัลกอรึทึมคลาสสิกที่ชื่อ Rabin-Karp กัน
วิธี Brute Force ที่เรียนๆกัน
ก่อนอื่นเลยเรามาดูวิธีแรกๆที่เขา(ในที่นี้หมายถึง “ทุกที่” 🤣) มักจะสอนกันก่อนก็คือ ให้เปรียบเทียบสตริงเข้าไปตรงๆเลย
อย่างเช่น
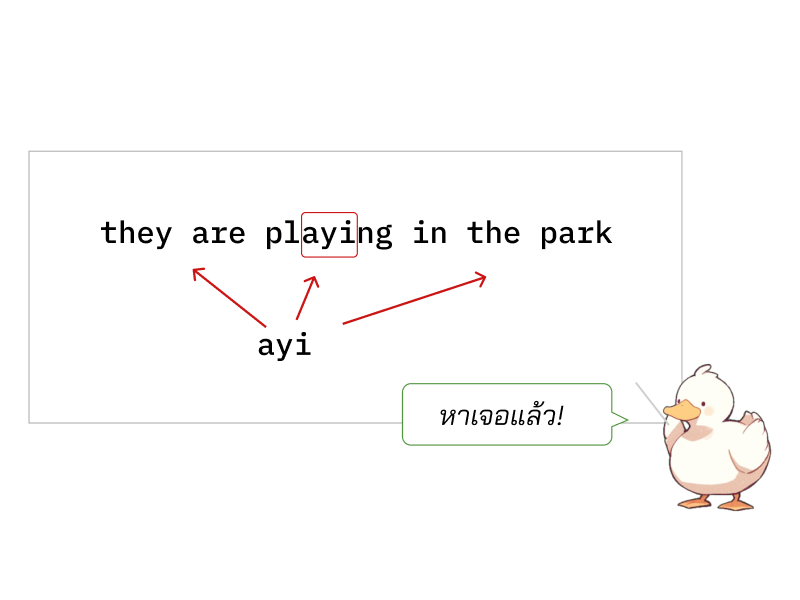
ถ้าถามว่ามีคำว่า ayi ใน “They are playing in the park” ไหม
เราก็เอาตัวอักษรแรกของ ayi (a) ไปไล่หาในสตริงที่ต้องการตรวจสอบ ซึ่งถ้าเราเจอว่าในนั้นมีตัว a อยู่ก็ถามต่อว่าถัดจากตัว a นั้นเป็น ตัว y รึป่าว ถ้ายังใช่อีกก็ถามต่อไปเรื่อยๆจนกว่าจะเจอครบคำว่า ayi
 เปรียบเทียบสตริงย่อย `ayi` โดยการมองหาตัวอักษร `a` ในสตริงหลัก
เปรียบเทียบสตริงย่อย `ayi` โดยการมองหาตัวอักษร `a` ในสตริงหลัก
ในกรณีตัวอย่างหลังจากไล่หาตัว a เราก็ไปเจอที่ are แต่ตัวถัดไปจาก a มันไม่ใช่ y ที่เราต้องการหา ก็เลยยังต้องหาต่อไป จนไปเจอตัว a ที่ playing ก็เลยไล่ถามตัวถัดไปใหม่จนครบสตริง ayi
ฟังดูก็ make sense ดี แล้วก็เขียนไม่ยากด้วยใช่มะ?
ปัญหาของวิธี Brute Force
ทีนี้ลองมาดูอีกตัวอย่างนึง
ถ้าจะหาคำว่า add ใน adadadadadadadad
 เทียบหาสตริงย่อย `add` โดยการมองหาตัวอักษร `a` ในสตริงหลัก
เทียบหาสตริงย่อย `add` โดยการมองหาตัวอักษร `a` ในสตริงหลัก
จะเห็นว่าเราต้องเปรียบเทียบตัวอักษรทุกตัวจนถึงตัวสุดท้ายในทุกๆครั้งที่เช็คคำว่า add เพราะตัว a ก็เยอะแถมยังต่อหลังด้วย d อีก
มันก็เริ่มจะฟังดูไม่ค่อยโอเคละ แล้วถ้าสตริงเป็นลักษณะคล้ายแบบนี้แต่ยาวขึ้นมากๆล่ะ?
ก็คงจะไม่ดีสักเท่าไหร่ถ้าจะเอาวิธีนี้ไปใช้ในอะไรที่ต้องการการประมวลผลที่เร็วมากๆ…
จริงๆ แล้วมันก็มีวิธีอื่นๆ ที่สามารถใช้หาสตริงย่อยนะ และมีประสิทธิภาพมากกว่าการไล่ดูทีละตัวตรงๆ ในทางทำโจทย์แข่ง จะมีที่นิยมใช้กันสองตัวคือ KMP และ Rabin-Karp เพราะเขียนไม่ยากมากและใช้เวลาในการทำงานน้อย
ในโพสต์นี้เราจะพูดถึงแต่ Rabin-Karp (เพราะมันเขียนง่ายกว่า KMP 🤣; เอาจริงๆไว้พูดทีหลังแหละ คอนเซปต์มันล้ำเกินไปยังหาวิธีทำบนเว็บดีๆไม่ได้)
Rabin-Karp Algorithm
Algorithm นี้จะอาศัยหลักการที่ชื่อว่า Rolling Hash มาเพื่อทำให้การเปรียบเทียบข้อมูลทำได้เร็วขึ้น เพราะถ้าสังเกตดูตอนเปรียบเทียบสตริงในวิธีก่อนหน้านี้ จะเทียบทีนึงก็ต้องค่อยๆเทียบทีละตัวอักษรซึ่ง ถ้าทำบ่อยๆก็จะช้า แต่ถ้าเปลี่ยนใหม่เป็นเทียบแค่ตัวเลขตัวเดียว มันก็ทำได้เร็วขึ้นเยอะเหมือนกัน
Rolling Hash
มันเป็นการแปลงสตริงให้กลายเป็นตัวเลขเพื่อที่จะได้เอาไปใช้เปรียบเทียบ โดยจะใช้หลักการของเลขฐานมาใช้คำนวณ คิดซะว่าทั้งสตริงคือเลขฐานที่ฐานมีค่าเยอะประมาณนึง เราจะเรียกเลขฐานนี้ว่า หรือก็คือ เราจะมองสตริงเป็นเลขฐาน นั่นแหละ
โดยวิธีที่เราจะทำคือสร้างฟังก์ชัน hash เพื่อแปลงตัวเลขฐาน ที่ว่านี้ ให้กลายเป็นเลขฐาน ที่เราคุ้นๆตานี่แหละเพื่อที่จะได้เปรียบเทียบได้ง่ายๆ
สมการแปลงเลขฐานก็ใช้แบบปกติได้เลย แค่ตำแหน่งอาจจะมีการเปลี่ยนแปลงบ้าง เพราะเราทำบนสตริง
โดย แทนขนาดของสตริงที่เอามาใช้ hash และ แทนเลขที่เราเลือกเองได้
ตัวอย่าง:
ในกรณีนี้เราจะแทนให้ตัวอักษร a = 1, b = 2ไปเรื่อยๆจนถึง z = 26
และค่า เพราะเราต้องการค่า
ที่มากกว่า 26 เพื่อให้มันมากกว่าจำนวนตัวอักษรที่มีในภาษาอังกฤษ และเป็นจำนวนเฉพาะ
สมมติถ้ามีตัวพิมพ์ใหญ่ด้วยก็จะมีตัวอักษรทั้งหมด ตัว เราก็ควรเลือกค่า เป็นจำนวนเฉพาะที่ใกล้เคียง ซึ่งจะใช้ หรือมากกว่าก็ได้
ทีนี้ลักษณะสำคัญของ rolling hash คือ ในกรณี input เปลี่ยนแค่นิดหน่อย มันไม่จำเป็นต้องคำนวณ hash ใหม่ทั้งหมดเหมือน hash ทั่วไป
อย่างตอนแรกที่เราคำนวณ hash ของ abc ไว้แล้ว ถ้าเราอยากจะหาว่า hash ที่แทน abcd คืออะไร ก็สามารถคำนวณโดยเพิ่ม d เข้าไปเลยก็ได้
จาก abc:
ไปเป็น abcd:
จะเห็นว่า hash ที่เปลี่ยนหลังจากเพิ่มตัวอักษรท้ายสตริง มีค่าเท่ากับค่า hash ก่อนเพิ่มคูณด้วย แล้วค่อยบวกค่า hash ของตัวอักษรตัวใหม่ หรือเขียนได้เป็น
เมื่อ แทนสตริงขนาดเท่าไหร่ก็ได้ และ แทนตัวอักษรตัวเดียวที่เพิ่มเข้ามาใหม
อีก operation นึงที่ทำได้คือการเอาตัวอักษรออกจาก hash
ถ้าอยากจะเอาตัวอักษรหน้าออกก็ทำได้โดยการลบออกธรรมดาๆ เลยนี่แหละ
แล้วพอเราสามารถคำนวณเลข hash จากการเพิ่ม/ลด ขนาดของสตริงได้ ปัญหาก็ก็เหลือแค่คำนวณค่า hash ของแต่ละบล๊อกของสตริงหลักก็พอ
 คำนวณ hash ของแต่ละบล๊อก
คำนวณ hash ของแต่ละบล๊อก
ซึ่งการคำนวณ hash ของแต่ละบล๊อกก็ไม่ได้ต้องคำนวณใหม่ตั้งแต่เริ่ม (เพราะไม่งั้นก็ไม่ได้เร็วกว่าวิธีเดิมอ่ะนะ) เพราะเราสามารถแก้ค่า hash ที่เราคำนวณมาก่อนหน้าให้กลายเป็นค่าถัดไปได้ โดยการเอาตัวหน้าออกแล้วเพิ่มตัวหลัง
อย่างในตัวอย่างคือเอาตัว a ออกจากด้านหน้า และเพิ่ม d เข้าไปด้านหลังสตริง
ซึ่งก็ทำได้ไม่ยากและให้โปรแกรมคำนวณส่วนนี้ก็เร็วกว่าให้มันเทียบทั้งสตริงเยอะ
แต่บางทีเลขมันก็เยอะมากจนมัน overflow ได้ถึงแม้จะใช้ long long(เลข 64 bits) ก็ตาม เขาก็เลยจะใช้จำนวนเฉพาะที่ใหญ่มากตัวนึง (นิยมใช้ 1e9 + 7) มา mod เพื่อทำให้เลขมันไม่ทะลุไปเยอะเกิน
การเขียน Rabin-Karp
เล่ามาตั้งนานกว่าจะได้เข้าเรื่อง Rabin-Karp…
Rabin-Karp เนี่ย concept คือ Rolling Hash เลย ก็คือไล่เช็กค่า hash ที่ได้ของแต่ละบล๊อก เพิ่มเติมคือเอาไปเทียบกับสตริงที่ต้องการจะหาด้วย
คำนวณ hash ของแต่ละบล๊อกเหมือนเดิม
ก็คือเก็บค่า hash ของสตริงที่จะหา อย่างเช่น add ก็คำนวณ เก็บไว้ แล้วไปไล่เทียบทีละบล๊อกของสตริงหลักเลย และมันก็เป็นไปได้แค่ 2 แบบ
- ถ้าได้ค่า hash ไม่ตรงกัน ก็ไม่ใช่แน่ๆ และเลื่อนตำแหน่งที่หาไป 1 ตำแหน่งเพื่อหาต่อ
- ถ้าค่า hash ตรงกันก็อาจจะเป็นสตริงย่อยก็ได้
ทีนี้ถึงเราได้ hash ตรงก็ไม่ได้แปลว่าจะเป็นสตริงย่อยเสมอไป
มันมีโอกาสที่เกิด collision หรือเลข hash ซ้ำกันได้อยู่ (แค่น้อยมากๆ) แต่ถ้าต้องการความถูกต้อง ก็สามารถ loop เพื่อเช็กตรงๆที่ตำแหน่งนั้นอีกทีก็ได้
หรือจะใช้อีกวิธีคือสร้าง modulo มาอีกชุดนึง เพื่อให้มีค่า hash เพิ่มอีกหนึ่งชุด จะได้ลดโอกาสการ collide โดยปกติแล้วใช้ modulo สัก 2-3 ตัวโอกาสก็น้อยมากพอแล้ว
Time Complexity
เราจะได้ว่า Rabin-Karp มี time complexity อยู่ที่ โดยที่ คือ ขนาดของสตริงหลัก และ คือ ขนาดของสตริงที่ต้องการหา เพราะว่าตอนเราคำนวณ hash แต่ละบล๊อกของสตริงหลัก จะใช้เวลา และ hash ของสตริงที่ต้องการหาก็ใช้เวลา
พอตอนจะมาเทียบก็เหมือนมองหาตัวเลขนึงใน array ธรรมดาซึ่งใช้เวลา รวมกันก็เลยเป็น
ซึ่งเร็วกว่าวิธี Brute Force ที่ต้องเทียบทีละตัวอักษรที่ใช้เวลา อยู่


